

Table of Contents
- 1.Introduction
- 2.Exercise-submission flow
- 2.1.Going trough the steps
- 2.1.1.exercise distribution
- 2.1.2.exercise submission
- 2.1.3.unit tests
- 2.1.4.exercise correction
- 2.2.Additional advantages
- 2.1.Going trough the steps
- 3.Problems with multiple server instances and high administration effort
- 3.1.Administration
- 3.2.User database
- 3.2.1.Repository for a lecture
- 3.2.2.Isolated developer
- 3.2.3.Student groups
- 4.Inner source
Introduction
This article should handle the question why a university or other academical institutions should have a central version control system (VCS) for sharing source code. Both the educator and the learning people should have access to the same platform.
VC has many advantages: For exchange in a team, sharing your code or versionizing just your own work.
si618 makes a nice list of questions about problems that occur during programming. They all result in the same answer: VCS:
- Made a change to code, realised it was a mistake and wanted to revert back?
- Lost code or had a backup that was too old?
- Had to maintain multiple versions of a product?
- Wanted to see the difference between two (or more) versions of your code?
- Wanted to prove that a particular change broke or fixed a piece of code?
- Wanted to review the history of some code?
- Wanted to submit a change to someone else's code?
- Wanted to share your code, or let other people work on your code?
- Wanted to see how much work is being done, and where, when and by whom?
- Wanted to experiment with a new feature without interfering with working code?
I will not repeat the advantages of VCSs itself, because of there are already many articles in the world wide web. So I assume the advantages and how it basically works are already known by the reader.
Instead I will focus on the topic regarding universities. This includes the actual state of the art and why they are bad. Also how the actual situation could be improved with a central VCS server and a central user base.
To me: I am a master student at the Department of Informatics at the Technische Universität München. It is a technical university so source code is a daily business for everyone. I have joined many lectures where a VCS would have been helpful, but I was also a tutor in two lectures with code intensive exercises. So I have experience from both sides. But I am not an employee, so take thoughts about their work-flow with caution.
I have my understanding from my university but this article should be valid for anybody. So I will write about my experience, my impressions and what I would improve.
Lecturer often provide exercises for practical experience and for feedback students can often submit them. In the first chapter I will describe how it actually works and that a VCS could be nicely integrated in such a process.
In the second chapter I will focus on how VCSs is actually used in my university and that multiple VCS servers is a disadvantage and that unnecessary resources are consumed. Especially multiple user databases are a problem and students are excluded from them so that they have no collaboration platform.
In the last, short chapter I will describe that inner source could be productive method.
I often use here git as an example for some things, but everything could be generalized to any VCS.
Exercise-submission flow
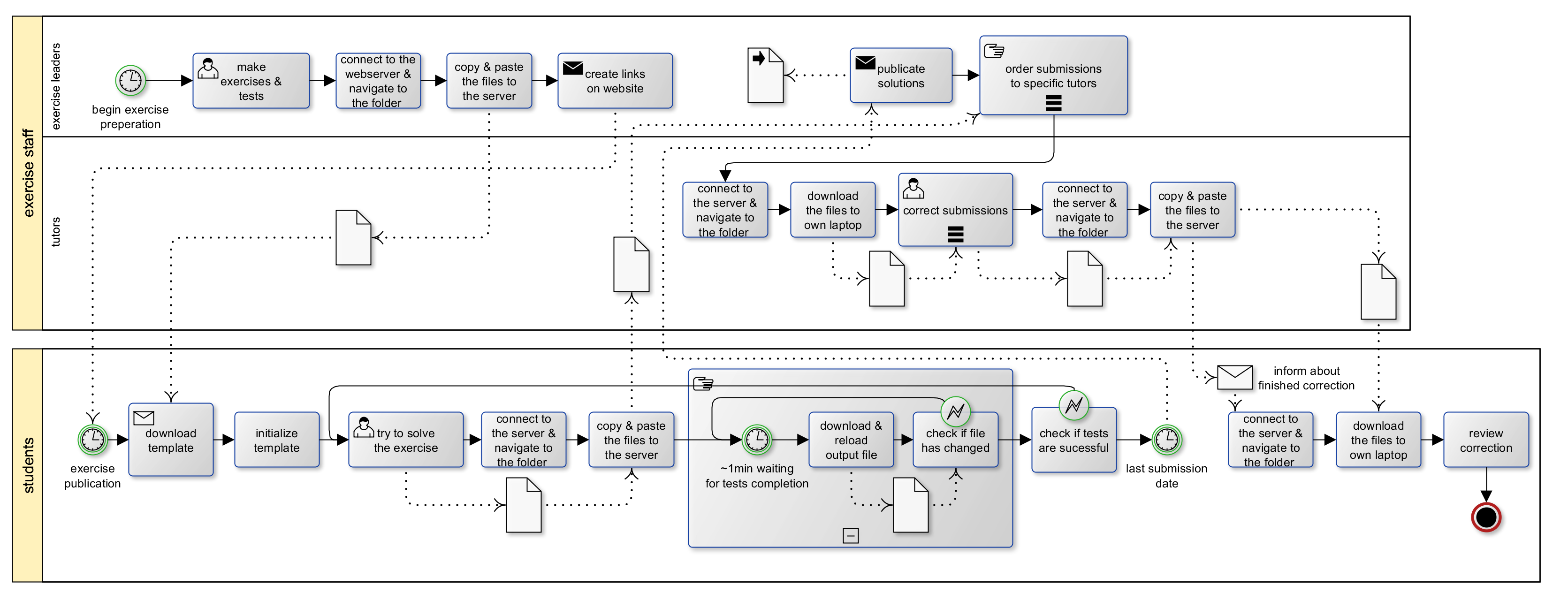

To practise the theoretical content of a lecture, it is common to provide exercises. In the most cases a exercise sheet is published every week and the student has 7 days to solve it. If the lecturers are encouraged the students have to submit their solutions to get feedback and a grade.
Of course there is some kind of management necessary to collect the submissions form the students.
In general problems are that you have to manage multiple parties and that you have to synchronize directories. git is such a tool to synchronize content, but actually it is mostly still done manually.
Going trough the steps
In the following I will go though the steps of such a exercise-submission flow. These steps are visualized in the Business Process Modelling Notation (BPMN) diagrams, one with a file server as a share point and one with git.
exercise distribution
After the exercise leaders prepare the tasks of the actual week they have to distribute it. In general the exercise sheet will be a PDF. The code template, if any, is packed into a zip-file. Both files will be uploaded to a directory on a web-server and the homepage is adjusted with two new links to those files. Push the files via git to a public repository, where the students have access to, is simpler I think.
A student will go to the web-page, download the files, copy the zip to his working directory, extract the zip and initialize his programming environment. On the git side the student must only run the command git pull.
exercise submission
The submission is often done via a file server, where the student have access to via SSH or FTP. The files must be placed at a specified directory where a script can find the files.
First problem here is the user accounts on the file server. For every semester and for every course the student gets a new user account, normally via a piece of paper at the first tutorial or via e-mail. Managing (for both sides student and lecturers) so many user accounts is quite uncomfortable.
The second one is, that the submission is quite annoying. Normally you connect to the server, navigate to the submission folder, copy the files locally and paste it on the server. You make no diff and always overwrite all files on the server regardless if they have changed or not. Not very efficient (Source files are not very big, so it is often a not very big deal). With git you must configure the remote only once and the command git push will then transmit only the changes to the previously specified remote. Much more comfortable.
unit tests
The submission process becomes more annoying, if the server runs unit tests. You have to repeat the upload procedure every time you want to test your code, which is quite often. Unit tests itself are a good idea. Every student makes errors and with tests the chance is much higher that he finds these errors. This will turn out in a better code quality and the student must dig into his own code to correct his failure, which result in a much better understanding of the scope.
The tests on the server are triggered trough a CRON job, which runs every x min (usual is 5-10 min). The student have to wait not only until the tests are finished also the time until the tests begins, which are up to x min. The results of the tests are normally written into a text file on the server. That means the student have to download the text file again and again until the content of the file changes.
For this use case, so called Continuous Integration (CI) Server are invented. Immediately after git push the git server sends a hook to the CI server to trigger the tests. On the CI web-page the student can directly see the actual test results. CIs are designed for that, so why not use them?
There is another method for submission: Sending it as E-Mail attachment to the tutor. This is simpler, because of the lecturers do not have to set up a server and a maybe faulty CRON job or other scripts could not fail. But order multiple submission e-mails and download and extract every e-mail attachment is very annoying for the tutor. Also you can not balance the submissions to the tutors (so that every tutor have to correct the same amount of submissions) and e-mail is in general a bad protocol for file exchanging. So it is quite a bad idea, but still the most simple one.
exercise correction
At least, if the tests succeed and the student think he can submit finally his files, he have to just wait until the submission time frame expiries. After that a CRON job will collect a bunch of student submissions (about 15-25 usually) and copy them to the tutors folder. The tutor can now directly download all submissions at once. Then the tutor will correct them and assess them. But what to to with the feedback for the submission?
There are different approaches for that.
One is to write a e-mail with some comments to every student. Is often done, but I personally don't like it. Managing so many e-mails is uncomfortable and it is complicated to refer to a specific line in the submission.
Another one is to use the student submission folder, which the tutor have normally write access to. But to navigate to every student folder and copy there the correction is very annoying. So annoying that normally every tutor write it's own script, which copies the corrections from within the structure of the download files to the student folders. Often those scripts also include sending a e-mail to the students to inform them.
git seems to be here also simpler. To get the submissions just pull a list of student's git repositories (there are already programs for that), then write your feedback and push again. Since git versionize everything you have still a unmodified copy of the submission. Modern git servers automatically informs repository participants (== the student here) about changes.
You maybe think many of the problems I describe here are not a so big deal, but at least they are quite annoying. Version Control Systems like git are invented to improve such situations, so why not use it?
Additional advantages
No programmer would have the idea to do a project without version control, but in lectures we have this idea, what? Of course version control is also very convenient here. I use an own git repository for every programming exercise I have done, since it is really useful, especially for backup and that you loose no code under any circumstances. So why not use the same git repository also for submission?
Like I said, git is used on every real project. So it is a good idea to utilise the students with git from the beginning of their studies, so that they can work practised with it. Well, a university should educate their students, including such common tools. We prevent that the students have some years later the problem to think "git what is that strange thing?" (that's really the case and many workers fear of it) if they work on a real project (or another lecturer uses git exceptionally).
Sometimes you can make the exercises in small groups (about 2-3). Exchanging source code with your team members via e-mail or a file server and not with git is awful, but sometimes you have to do it like that.
Modern git server include reviewing tools. They can be used as an alternative to provide feedback to the students.
The exercise can be published also via the issue system of the git server and therefore integrates better into the environment then a PDF (you can view your exercise directly on the git server web-page of your repository and IDEs can also view them locally). They are maybe also a bit more nice since it looks more like a real project.
Often the tutors review the exercises before thy are published. Actually this is done via e-mail or in meetings. A git server provides better possibilities like the issue management, pull/merge requests (tutors have sometimes good ideas for improvement) and of course the review tools.
For the submission you mostly only need the source code, but IDEs and compiler create many temporary files, which are sometimes even hidden. You don't want these files on the server and so you instruct the students on every possible place, that they should only submit the source, but trust me, many will not follow these instructions. git support .gitignore files where you can exclude temporary and unwanted files, so that no student is able to push them.
Problems with multiple server instances and high administration effort
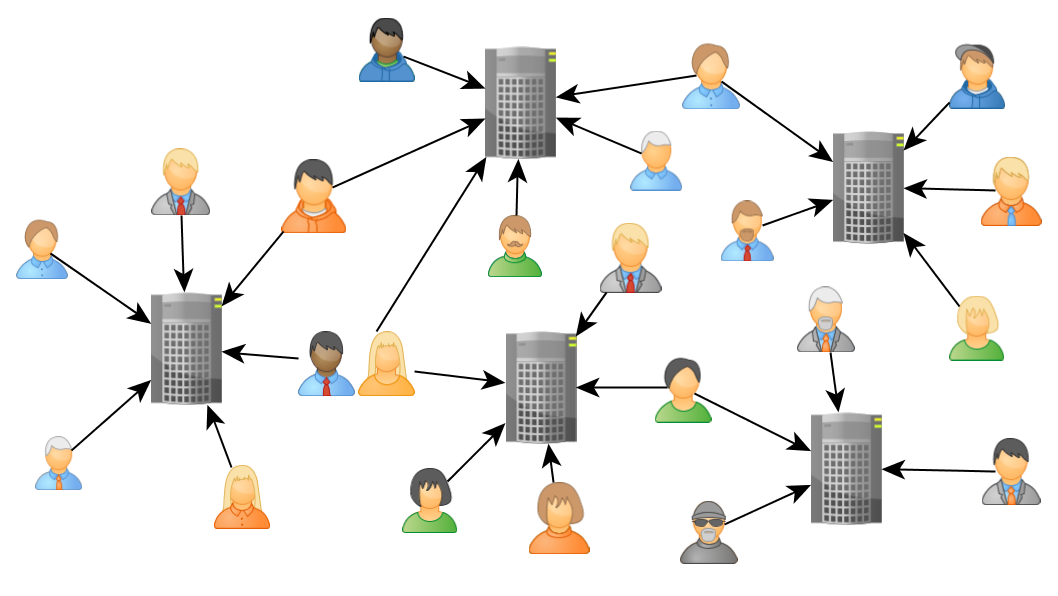
Like I said already, no programmer would work without version control. I think the most common solution is now to use an own server instance. I do not really know how many, but I estimate minimum one per chair. I also saw it, that for a course an own server was set-upped and destroyed afterwards, which is quite bad, if you do not have a backup of your files.
Administration
Every server has the same requirements: Providing repositories where only a set of people have access to (== user management). But anyway, everyone have its own server, although there is no need for it. Hence, there are some disadvantages rising with so many instances, which I will describe in the following.
First of all every server had to be administrated. There are many qualified people for that, but it is still a quite big afford requiring many working hours for maintaining the server. Well all of them gets paid for it, doing quite the same work. Multiple server doing the same work consumes unnecessary power and therefore more running costs. Especially git server have only something to do if someone access them. If only a few people use a particular server, it is most time idle. So they consuming power for the base system but processing nothing. Well many of them run on a VM, so the last argument is not that critical, but anyway merging the servers to a single one would theoretical save different resources.
My experience is primary from my own department. Here in computer science quite every one is a little administrator and it is no big deal for them to manage a git server. I have not really an insight into the other departments, but I heard that own git servers are not so common. I don't know what are the alternatives for them but once I heard from a creepy story where a git repository was initialized into a Dropbox folder to use that service for synchronization. Horrible! Maybe it was only a rumour, but I could imagine that. Still it is maybe a good idea to take some guys by the hand?
User database
A more critical argument is the user database, which is used for access control of the different repositories. The problem is that every server has its own user database. Theoretical the data-centre provides a central user database, but well no one use it.
Repository for a lecture
It is quite rare, but sometimes git is used in a lecture. Because no one want to set up a server configured to support the university central user database, every time a local one is generated. git works with the SSH public key authentication mechanism. A half of the students must firstly solve the mystery what a public key is, but after that the lecturer orders everyone to send him per e-mail the public key. Then the lecturer have to manually save the key from the e-mails to the server and activate it. The normal student will generate a new public-private key pair for every lecture and without a good key management chances are high that the student will lost some of his private keys during time. Replacing the lost key with a new one is also fussy, because the lecturer has to identify the old one and replace it by hand. Not very awesome or? In a central git environment, you have also a central user management, therefore central key management and so only one key for all repositories is required.
Overall the management could be more efficient or simpler I think, especially you have a web frontend where the students can make a part of the configuration themselves. See also the "Exercise-submission flow" chapter for how the lecture integration of git repositories works.
Isolated developer
An additional problem is what I call the developer power gets isolated. If someone do not have an user account, he does not have the ability to participate to a project on a server. But what if he wants to? Well he needs an own extra user account maybe only for one project. But maybe the internal rules of the server administration does not allow to add external users except maybe under special circumstances. Or there exist no rules yet and its unclear what to do. Often the server administrator have to create every user account which is quite fussy.
Often the participation is quite low: Only doing a single Merge/Push request for a single bug you have found, just submit a simple issue or someone just wants to show you something in his code. These simple things are important, but the process for getting an user account is much to complicated that this will ever happen. See also the 'Inner source' chapter, which is related to this paragraph. Therefore this prohibit efficient communication and cooperation.
Student groups
For students this is more complicated then for employees. They have no direct connection to a chair, but also not have any own resources. So they have in general no access to any git server (except it is part of a lecture and in some other exceptions). But nevertheless they want to participate sometimes to a project, because they have an idea, or they just want to share code with colleges to work on some together.
For example they want to play around with some code shown in a lecture. It could be part of the slides or an exercise (not always the lecturers offer a sharing platform if the students should or simply want to work in a group). So what are the possibilities? Sending code snippets or files with a chat application or via e-mail - very bad, but it's done. Using file synchronization tools like Dropbox or Google Drive - bad, but it's also done. Dropbox & Co. have the problem that they are not really suitable for file synchronization, more for sharing. They can not handle merge conflicts for example.
Indeed one of the biggest problems is to come to an agreement to one service. "Have you service A?" "No and I don't want!"; "Have you service B?" "No, the company behind B is evil!". These are some of the "discussions" you have at the beginning. I have quite everywhere an account to minimize such problems. I even install a GitLab instance on a private server to have a place for exchange. Since I am the administrator, I can just create an account for other ones. And this is what I have done, before I really asked my team members if it's OK for them.
Especially in former times every code sharing platform offer only public repositories, so you often can't use them. Today there are some, but they are not very known and often not used.
Well the act that you have to ask for a sharing platform is already a problem. Because of it is laborious asking for it, you do not want to start your dialogue with that. Normally you directly look for a workaround for it. For example to submit a small exercise I simply make the project public with the hope that no other student will find it.
To summarize that, it would be much simpler, if the university would provide a central platform where everyone agrees using it and where you have a central user database so that you can always use the known ID of the university member.
Inner source
Firm-internal open source or like it now called inner source is a practice where the benefits of open source are applied inside a company. I am not an expert in that filed, so this is more just to mention this method. The most important workflow components of open source are after Sijbrandij:
- Visibility: all software projects are by default visible to all employees
- Forking: everyone who can see the code, can create a copy (fork) where they can make changes freely; these forks are visible for everyone.
- Pull/merge requests: even people outside the project are able to suggest changes and you can have a conversation about the code with line comments.
- Testing: software includes unit- and integration-tests so that changes can be made with less fear of causing problems.
- Continuous Integration: every proposed change is automatically tested and the result is shown with the change.
- Documentation: all software projects include a readme that describes what the software does, why that is important, how run it and how to develop it.
- Issue tracker: there is a public issue tracker in which everyone can submit a bug or ask a question
The idea behind inner source is that you want to archive theses advantages also in a smaller scope, e.g. your company member and not the world. A university is not a economic interested firm, however the benefits still holds if you just enlarge your developer scope and maybe also integrate students. So the resulting benefits of inner source are after Dirk Riehle et al. (“Open Collaboration within Corporations Using Software Forges.” IEEE Software, vol. 26, no. 2 (March/April 2009). Page 52-58.):
- Volunteers. Even within traditional top-down structured software development organizations, projects can gather internal volunteer contributions.
- Motivated contributors. Volunteers choose projects according to their own interests rather than by assignment. The decision to contribute is theirs and gives them opportunities to gain reputation and visibility in the company beyond their assignments.
- Better quality through quasi-public internal scrutiny. When development within the corporation is open, developers typically feel an extra incentive to strive for high-quality contributions.
- Broad expertise. Because volunteers can join from across the organization, they can significantly broaden the expertise available to a project. This helps projects reach goals more quickly at higher quality. Specifically, it can help fix problems more quickly and either prevent mistakes or capture them earlier.
- Broad support and buy-in. With volunteers from across the organization, projects find a broader base and support in the organization.
- Better research-to-product transfer. Research projects can get expertise and volunteers from downstream product units, which can ease the research-to-product technology transfer.
For further informations about inner sourcing see this list of articles.
A central server, where all code lives, is one of the preconditions that inner source could exist (see above section "User database"). Internal projects are more exiting then all other ones, so the interest is here higher. Professors sometimes talk in a lecture about projects at their chair and invite students if they have interest. But this is too unconcrete. To gain interest some sort of information must exist. The classic way would be a homepage, but especially for small programming projects making one is too longwinded. The modern strategy is a repository with a README file just with some small information, which is in most times enough. The accessible source code makes sure that everyone can first play around with the code. The result could be a Merge/Pull request with a little feature or a bug fix, if he found one. Also the interest in the project could raise and he maybe participate over a longer time. Or it is useful to simply have some other code as an example for own experiments.
To summarize everything, I think VCS would be really an enrichment. There are some problems that are solved with it and it would be more professional than the old school strategies. Feel free to use the comments if I made mistakes, have critics or simply have something to say.